是什么
为什么
如何去使用
Hadoop
Hadoop简介:http://hadoop.apache.org
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
模块
特点
分布式存储系统HDFS (Hadoop Distributed File System )POSIX
提供了 高可靠性、高扩展性和高吞吐率的数据存储服务
分布式计算框架MapReduce分布式计算框架(计算向数据移动)
具有 易于编程、高容错性和高扩展性等优点。
分布式资源管理框架YARN(Yet Another Resource Management)
负责集群资源的管理和调度
HDFS 存储模型:字节*
文件线性切割成块(Block):偏移量 offset (byte)
Block 分散存储在集群节点中单一文件Block大小一致,文件与文件可以不一致
Block可以设置副本数 ,副本分散在不同节点中副本数不要超过节点数量
文件上传可以设置Block大小和副本数
已上传的文件Block副本数可以调整
大小不变 只支持一次写入多次读取,同一时刻只有一个写入者可以 append 追加数据
在一个文件中 Block 的大小保持一致,在不同文件中 Block 的大小可以不一致。
注意:同一个机器不能存储两个相同的副本,副本应该存在不同的机器上的。
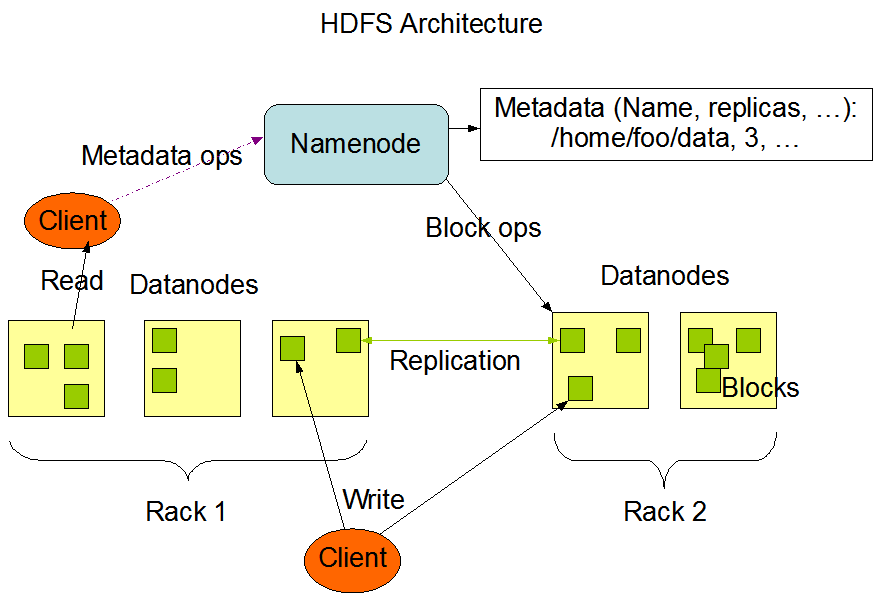
架构模型
文件元数据 MetaData,文件数据多节点 保持心跳 ,提交Block列表
NameNode(NN)
定义
主要功能
基于内存存储 :不会和磁盘发生交换
接受客户端的读写服务位置信息
注意: NameNode 记录快照时是不包括 DataNode 的位置信息的。
NameNode 持久化
NameNode 的 metadate 信息在启动后会加载到内存
metadata 存储到磁盘文件名为”fsimage”
Block 的位置信息不会保存到 fsimage edits记录对 metadata 的操作日志
若 NameNode 发生故障,首先会从磁盘 fsimage 文件中恢复到上一次记录快照的状态,然后在根据 edits 记录执行从上一次记录快照的时刻到 NameNode 宕机前的操作。
DataNode(DN)
本地磁盘目录存储数据(Block),文件形式
同时存储Block的元数据信息文件
启动 DN 时会向 NN 汇报 block 信息
通过向 NN 发送心跳保持与其联系(3秒一次),
如果 NN 10分钟没有收到 DN 的心跳,则认为其已经 lost,并 copy 其上 的 block 到其它 DN
注意:若一台 DN 宕机了,NN 10 分钟才会认为该 DN 已经丢失。这时 NN 会根据之前该 DN 上传的 block 信息,去其他 DN 上寻找这些 block 的副本。
HDFS 优缺点
优点
缺点
1. 高容错性 2. 适合批处理 3. 适合大数据处理 4. 可构建在廉价机器上 低延迟数据访问
SecondaryNameNode(SNN)
它不是NN的备份(但可以做备份),它的主要工作是帮助NN合并edits log,减少NN启动时间。
SNN合并流程
在 PN 合并之前,会将 edits 和 fsimage 文件发送给 SN,然后 PN 创建一个新的 edits.new 文件继续记录 PN 的操作。
PN 将之前的 edits 和 fsimage 发送给 SN 后,SN 会将 fsimage 加载到内存,edits 也加载到内存
根据 edits 中操作记录执行相应的指令,当 edits 的所有操作记录对应的指令执行完毕,会生成一个新的 fsimage.ckpt 快照。
将新生成的 fsimage.ckpt 再发送给 PN ,这时 PN 就拥有 edits.new 创建之前的快照记录
若 PN 发生了宕机,可以根据 fsimage 和 edits.new 恢复到宕机前的状态
副本放置策略
第一个副本:放置在上传文件的 DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在于第一个副本不同的 机架的节点上。
第三个副本:与第二个副本相同机架的节点。
更多副本:随机节点
注意:第一个副本与第二个副本不在同一台机架上
服务器的种类: 1.塔式(就像家里的台式机主机箱那样)2. 机箱(像 DVD机那样)3. 刀片(像厨房放刀的刀架)
HDFS 写流程*
Client:
注意:
client 向 DataNode 写数据,分为许多小数据包,一次次的传递,直到所有数据包都发送完毕
HDFS 读流程*
Client:
和 NN 获取一部分 Block 副本位置列表
线性和 DN 获取 Block,最终合并为一个文件
在Block副本列表中按距离择优选取
HDFS 发送请求到 DistributedFileSystem,DistributedFileSystem 会向 NameNode 索要指定文件所有块信息,并返回所有块副本信息(按副本顺序按距离排序)
通过 HDFS,可以读取文件任意块的位置
记: 分布式文件系统很好的支持计算层的本地化读取
HDFS文件权限 POSIX 与Linux文件权限类似
r: read; w:write; x:execute
权限x对于文件忽略,对于文件夹表示是否允许访问其内容
如果Linux系统用户zhangsan使用hadoop命令创建一个文件,那么这个文件在HDFS中owner就是zhangsan。
HDFS的权限目的:阻止好人错错事,而不是阻止坏人做坏事。HDFS相信,你告诉我你是谁,我就认为你是谁。
安全模式 namenode启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。
一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个操作不需要
SecondaryNameNode)和一个空的编辑日志。
此刻namenode运行在安全模式。即namenode的文件系统对于客户端来说是只读的。(显示目录,显示文件内容
等。写、删除、重命名都会失败)。
比例(可设置)的数据块被确定为“安全”后,再过若干时间,安全模式结束
当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数,系统中数据块的位置并不是由namenode
维护的,而是以块列表形式存储在datanode中。
集群
角色(进程)
功能
NameNode
数据元数据
block
偏移量,因为block不可以调整大小,hdfs,不支持修改文件
磁盘
面向文件,大小一样,不能调整
SN
NN & DN
心跳机制
client
搭建 Hadoop 伪分布式 准备 时间同步 1 2 3 4 5 type ntpdate # 安装 ntpdateyum install -y ntpdate # 同步网络时ntpdate -u ntp.api.bz
操作系统环境设置
1 2 3 4 5 # 在另外一台机器上远程执行 192.168.170.101 机器上的命令(验证)ssh root@192.168.170.101 'ls ~' $ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa # 生成密钥$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys # 对自己免密钥
1 2 3 4 rpm -ivh jdk-7u67-linux-x64.rpm # 修改 /etc/profileexport JAVA_HOME=/usr/java/jdk1.7.0_67 export PATH=$PATH:$JAVA_HOME
Hadoop 配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 tar xf hadoop-2.6.5.tar.gz mkdir /opt/sxt mv hadoop-2.6.5 /opt/sxt/ # 配置 hadoop 环境变量export HADOOP_HOME=/opt/sxt/hadoop-2.6.5 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # cd /opt/sxt/hadoop-2.6.5/# 进入 etc 目录中# 修改 Java 环境路径,export JAVA_HOME=/usr/java/jdk1.7.0_67# 目的是 hadoop 管理脚本操作机器不能读取 /etc/profile 文件,所以需要改 Java 的绝对路径vi hadoop-env.sh vi mapred-env.sh vi yarn-env.sh
1 2 将 localhsot 改为 node01 node01
1 2 3 4 5 6 7 8 9 10 <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://node01:9000</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /var/sxt/hadoop/local</value > </property > </configuration >
1 2 3 4 5 6 7 8 9 10 <configuration > <property > <name > dfs.replication</name > <value > 1</value > </property > <property > <name > dfs.namenode.secondary.http-address</name > <value > node01:50090</value > </property > </configuration >
配置文件
作用
etc/hadoop/core-site.xml
决定 NameNode 的启动
etc/hadoop/slaves
决定 DataNode 的启动
etc/hadoop/hdfs-site.xml
决定 SecondaryNode 的启动
启动 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 格式化$ hdfs namenode -format$ ls /var/sxt/hodoop/local/dfs/name/current/fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION # 启动 NN、DN、SN$ start-dfs.sh# jps 查看 Java 进程,是否有 NN、DN、SN$ jps3385 DataNode 3543 SecondaryNameNode 3674 Jps 3306 NameNode # 访问 http://192.168.170.101:50070
使用 1 2 3 4 5 6 hdfs dfs -mkdir /user hdfs dfs -ls /user hdfs dfs -mkdir /user/root hdfs dfs -D dfs.blocksize=1048576 -put hadoop-2.6.5.tar.gz # 展示当前目录,并显示文件大小 ll -h
搭建 Hadoop 全分布式 准备
NN
SNN
DN
node01
*
node02
*
*
node03
*
node04
*
搭建 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 # 关闭 Hadoop 伪分布式stop-dfs.sh # 配置节点 node02、node03、node04 的 java 环境 和 sshcat ~/node01.pub >> ~/.ssh/authorized_keys cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys # 以下操作针对 node01 ---------------------------------------------# 修改 Hadoop 配置文件# 编辑 etc/core-site.xml 文件<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://node01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/var/sxt/hadoop/full</value> </property> </configuration> # 编辑 etc/hdfs-site.xml 文件<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node02:50090</value> </property> </configuration> # 编辑 etc/slaves 文件node02 node03 node04 # ------------------------------------------------------------------# 在 node02、node03、node04 下创建文件夹mkdir /opt/sxt # 在 node01 节点的 /opt/sxt 目录下执行scp -r ./hadoop-2.6.5/ node02:`pwd` scp -r ./hadoop-2.6.5/ node03:`pwd` scp -r ./hadoop-2.6.5/ node04:`pwd` # 在 node01 节点上执行 ---------------------------hdfs namenode -format start-dfd.sh
在 node01 节点上执行 格式化
在 node01 节点启动 hadoop
Hadoop 2.x
主备 NameNode
JNN:集群(属性)
standby:备,完成了 edits.log 文件的合并产生新的image,推送回 ANN
ZooKeeper Failover Controller:监控NameNode健康状态,并向Zookeeper注册NameNode
Hadoop 2.x 联邦
联邦:不同应用间是相互隔离
通过多个namenode/namespace把元数据的存储和管理分散到多个节点中,使到namenode/namespace可以通过增加机器来进行水平扩展。
能把单个 namenode 的负载分散到多个节点中,在 HDFS 数据规模较大的时候不会也降低 HDFS 的性能。可以通过多个 namespace 来隔离不同类型的应用,把不同类型应用的HDFS元数据的存储和管理分派到不同的namenode中。
HA 高可用 准备
NN-1
NN-2
DN
ZK
ZKFC
JNN
node01
*
*
*
node02
*
*
*
*
*
node03
*
*
*
node04
*
*
搭建 Zookeeper 集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # 解压 Zookeeper 压缩包,并移动到 /opt/sxt 目录下# 配置 Zookeeper 环境变量# 到 zookeeper 目录下,进入 conf 目录下# 复制 zoo_simple.cfg 到 zoo.cfg# 修改 zoo.cfg 配置文件dataDir=/var/sxt/hadoop/zk clientPort=2181 # 配置 zk 集群,第一次启动按 serverid 区分 leader 和 fellowerserver.1=192.168.170.102:2888:3888 server.2=192.168.170.103:2888:3888 server.3=192.168.170.104:2888:3888 # 创建 /var/sxt/hadoop/zk 目录,将当前机器 zk 的 id 写入 myid 文件中mkdir /var/sxt/hadoop/zk -p echo "1">/var/sxt/hadoop/zk/myid # 分发 zookeeper 目录到其他机器上(node03、node04)scp -r ./zookeeper-3.4.6/ root@node03:`pwd` scp -r ./zookeeper-3.4.6/ root@node04:`pwd` # 在 node03、node04 机器上# 1. 配置 zookeeper 的环境变量 # 2. 增加 myid 文件,将当前机器 zk 的 serverid 写入
HA 搭建
逻辑到物理的映射
JNode 位置信息相关配置
出现故障的处理方式及 SSH 免密钥配置
hdfs-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 <property > <name > dfs.nameservices</name > <value > mycluster</value > </property > <property > <name > dfs.ha.namenodes.mycluster</name > <value > nn1,nn2</value > </property > <property > <name > dfs.namenode.rpc-address.mycluster.nn1</name > <value > node01:8020</value > </property > <property > <name > dfs.namenode.rpc-address.mycluster.nn2</name > <value > node02:8020</value > </property > <property > <name > dfs.namenode.http-address.mycluster.nn1</name > <value > node01:50070</value > </property > <property > <name > dfs.namenode.http-address.mycluster.nn2</name > <value > node02:50070</value > </property > <property > <name > dfs.namenode.shared.edits.dir</name > <value > qjournal://node01:8485;node02:8485;node03:8485/mycluster</value > </property > <property > <name > dfs.journalnode.edits.dir</name > <value > /var/sxt/hadoop/ha/jn</value > </property > <property > <name > dfs.client.failover.proxy.provider.mycluster</name > <value > org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider </value > </property > <property > <name > dfs.ha.fencing.methods</name > <value > sshfence</value > </property > <property > <name > dfs.ha.fencing.ssh.private-key-files</name > <value > /root/.ssh/id_dsa</value > </property > <property > <name > dfs.ha.automatic-failover.enabled</name > <value > true</value > </property >
core-site.xml
注意:hadoop.tmp.dir的配置要变更:/var/sxt/hadoop-2.6/ha ###
1 2 3 4 5 6 7 8 <property > <name > fs.defaultFS</name > <value > hdfs://mycluster</value > </property > <property > <name > ha.zookeeper.quorum</name > <value > node02:2181,node03:2181,node04:2181</value > </property >
HA 部署 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 第一次部署# 1.启动 node01、node02、node03 的 journalnodehadoop-daemon.sh start journalnode # 2.格式化 node01 dfshdfs namenode –format # 3.启动 node01 的 NN ,启动 node02 的 standyNNhadoop-daemon.sh start namenode # 在 node01 hdfs namenode -bootstrapStandby # 在 node02 # 4.格式化 zk hdfs zkfc -formatZK # 5.启动 hdfsstart-dfs.sh # 测试 kill -9 进程号 强制清除 # 第二次启动 1,启动zk 2,start-dfs.sh
SSH 免密钥的应用场景 1 2 3 4 5 1. 管理脚本管理服务的开启与关闭 2. 搭建 HA 时,ZKFC 需要控制自己及对方 ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa # 生成密钥 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys # 对自己免密钥
Windows 下开发大数据 添加 Hadoop 环境变量和指定用户
Eclipse 中自定义用户库
打开 Eclipse 的首选项:点击菜单栏下 window > Perferences
搜索 user ,即可找到 User Libraries 的位置并点击
点击 New 按钮,新建一个用户库,自定义库的名称
选择刚创建自定义用户库,点击 Add Exteral JARs …点击,选择需要添加 jar 包,最后确定即可
HDFS-api 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 public class TestHDFS Configuration conf = null ; FileSystem fs = null ; @Before public void before () throws Exception conf = new Configuration(true ); fs = FileSystem.get(conf); } @After public void after () throws Exception fs.close(); } @Test public void mkdir () throws Exception Path f = new Path("/hello" ); if (fs.exists(f)){ fs.delete(f, true ); } fs.mkdirs(f); } @Test public void upload () throws Exception InputStream is = new BufferedInputStream( new FileInputStream(new File("D:\\hello.txt" ))); Path p = new Path("/user/root/test-h.txt" ); FSDataOutputStream out = fs.create(p); IOUtils.copyBytes(is, out, conf, true ); } @Test public void download () throws Exception Path path = new Path("/user/root/test.txt" ); InputStream in = fs.open(path); FSDataInputStream fsin = new FSDataInputStream(in); OutputStream ops = new BufferedOutputStream( new FileOutputStream(new File("D:\\hadoop.txt" ))); IOUtils.copyBytes(fsin, ops, conf); } @Test public void testBlockLocation () throws Exception Path path = new Path("/user/root/test.txt" ); FileStatus fStatus = fs.getFileStatus(path); BlockLocation[] bkls = fs.getFileBlockLocations(fStatus , 0 , fStatus.getLen()); for (BlockLocation bkl : bkls) { System.out.println(bkl); } FSDataInputStream in = fs.open(path); in.seek(1048576 ); System.out.println((char )in.readByte()); System.out.println((char )in.readByte()); } }